Appearance
Cloud Firestore数据库
Firestore是一个实时数据库,它能快速可靠地存储数据,并且在设备离线时也可以工作。
注意
如果你不确定是否应该使用Firestore还是旧的实时数据库,请阅读官方比较文档。如果有疑问,我们建议你选择Cloud Firestore数据库,因为它更快、更便宜、更现代化、更可扩展,而且通常更强大。
文档和集合
Firestore数据库由文档和集合组成。文档包含数据,集合包含文档。文档还可以包含集合,即命名的子集合。
集合的优点是在访问它们时不需要完全下载。例如,如果你想为每个用户存储一个包含他的朋友信息的结构,你可以将该结构放入文档中,也可以将其转换为子集合(其中每个子项都是一个文档)。如果将其放入文档中,你会使文档变得更大,并且每次想从文档中获取一些数据时,你需要重新下载整个数据,只为了获取一个字段,而且从文档中获取其他数据也更加耗时。如果将其作为子集合,你可以单独获取每个朋友的数据,并且在获取玩家数据时不需要获取所有的朋友数据。
提示
集合的另一个优点是它们非常擅长在将数据发送给玩家之前进行过滤和排序。遗憾的是,GDevelop目前还不支持向集合发送查询请求。
有关Firestore数据模型的更多信息,请阅读数据模型指南。
访问控制
也许你不希望允许每个人都写入所有内容。否则,每个人都可以修改其他人的数据!为了选择谁可以访问什么以及如何访问,Firebase有规则系统。它与firebase身份验证相互操作。
你还可以拥有一个用户集合,在每个文档中(以用户UID命名)拥有他们的权限。例如,在这里,你可以允许具有验证权限的每个用户访问userdata集合中的自己的文档,并允许管理员访问globaldata集合中的文档: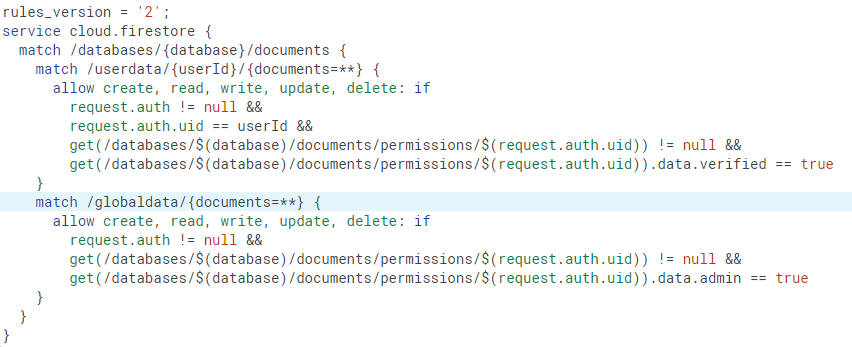
要详细了解如何编写规则,请阅读语法指南。
查询
查询是Firebase的一个功能,主要有两个用途:
- 过滤、选择和排序集合中的文档。
你可以构建一个查询,以对所需获取的文档应用条件和获取方式。 首先,要构建一个查询,您需要先创建一个查询。您可以从头开始创建一个查询,也可以复制一个已经建立好的查询。

接下来,您可以为查询添加一些过滤器。
值/文本过滤器
值/文本过滤器允许检查符合特定条件的所有文档。例如,您可以只选择在owner字段中具有当前用户UID的文档:

排序过滤器
提示
必须将此过滤器应用于查询,才能使用“跳过一些”和“限制”过滤器。
此过滤器允许自动按字段值对查询的文档进行排序。例如,如果您有如下所示的文档:
{ price: 69, name: 'Lamp oil'}, { price: 42, name: 'Rope'}, { price: 420, name: 'Bombs'}
并像这样使用过滤器:

那么查询中的文档将被重新排序如下:
{ price: 420, name: 'Bombs'}, { price: 69, name: 'Lamp oil'}, { price: 42, name: 'Rope'}
跳过一些过滤器
警告
在添加此过滤器之前,您需要将“排序依据”过滤器添加到查询中。
此过滤器允许删除在某个顺序文档的值之前或之后的所有文档。例如,如果我们将与“排序依据”过滤器相同的示例,并像这样使用过滤器:

那么查询将变为{ price: 42, name: 'Rope'},因为列表中在价格为69的文档之前的所有文档,包括价格为69的文档,都将被跳过/从查询中删除。
限制过滤器
警告
在添加此过滤器之前,您需要将“排序依据”过滤器添加到查询中。
此过滤器允许仅获取查询中的前X个或最后X个文档。例如,如果您以以下方式使用它:

那么只会保留第一个文档。如果我们使用与“排序依据”过滤器中相同的示例,只会保留{ price: 420, name: 'Bombs'}。
提示
通过结合限制和跳过一些过滤器,可以进行分页。
- 监听集合中的更改并获取文档及其内容
一旦您构建了查询(或仅创建一个空查询以针对集合中的所有文档),您可以观察查询或执行它。当您观察它时,每当符合查询条件的文档被添加、修改或从集合中删除时,它将“用查询结果替换传递变量的内容”。如果执行它,它将仅获取符合查询条件的文档,并将结果放入传递的变量中。The query result\n\n当查询完成时,它会将其结果存储在传递的结构变量中。结果会是这样的:\n\n{ size:undefined, empty: false, docs: [ { exists: true, id: \'文档在集合中的ID\', data: { the: \'文档的数据\' } } ] }\n\n例如,如果你想将第一个文档的数据转换为JSON格式,你可以使用以下表达式:\n\nToJSON(QueryResultVariable.docs[0].data)\n\n查询结果描述\n\nsize:匹配查询的文档数量\n\nempty:一个布尔值,如果没有匹配查询的文档,则为true\n\ndocs:匹配查询的所有文档的数组(按过滤器顺序排列)\n\n文档结果描述\n\nexists:一个布尔值,如果文档在集合中实际上不存在,则为false\n\nid:文档在集合中的ID(名称)\n\ndata:包含文档内部数据的结构\n\n例如,如果你想获取文档的数量